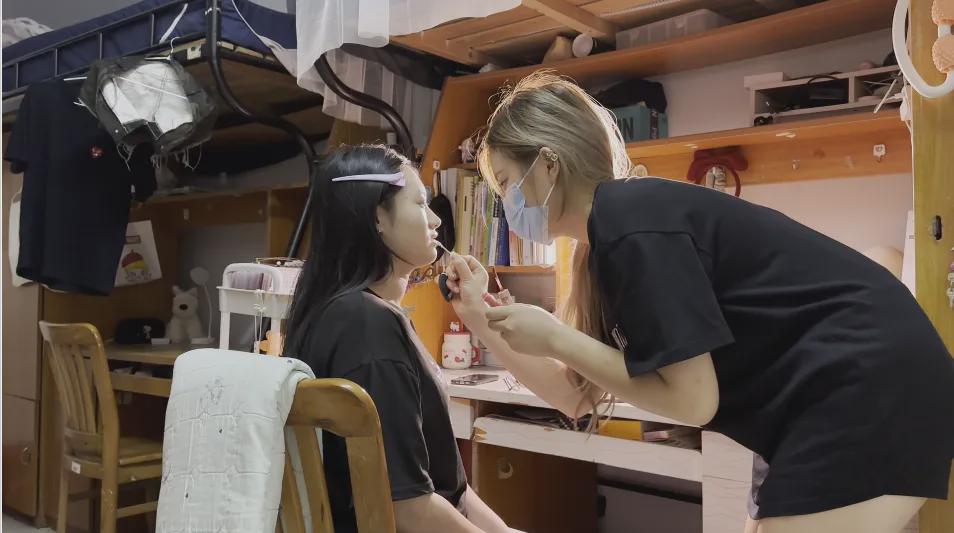requests安装命令
来源: 最后更新:23-02-02 12:34:19
-
通过前几节课的学习,我们大概了解了通过urllib模块怎么样获取数据、解析数据、保存数据得到我们想要的数据了,今天呢,就给大家介绍一个Python爬虫获取数据的另外一个方法requests库。那么urllib和requests哪个好?urllib和requests有什么区别呢?
1.requests库怎么安装
我们已经讲解了Python内置的urllib模块,用于访问网络资源。但是,它用起来比较麻烦,而且,缺少很多实用的高级功能。
更好的方案是使用requests。它是一个Python第三方库,处理URL资源特别方便。
requests库的安装与安装其他第三方应用一样(如下图):
第二步,发起请求。
首先我们需要判断请求类型。最常见的请求方式为 GET 和POST,我们可以通过右击检查-network-headers-Request Method可以看到该页面的请求方式为get

因此我们发起请求的格式为:
requests.get(网页地址)
第三步,获取网页内容。
首先我们需要判断我们获取到的网页是什么类型,同样可通过右击检查


-network-headers-Content-Type可以看到该网页的内容为text类型
因此我们获取网页的基本格式为:
response.text
如下图即可输出网页内容:

第四步,存储网页信息。
基本格式为:
with open(保存的文件名,读写模式,encoding=”utf-8″) as 变量:

变量.write(网页内容)
以上就是关于requests的用法,我们可以结合之前学过的内容,想想urllib与requests哪个更加方便,以及对于有反爬虫机制的网站,又应该如何用requests获取内容信息,下节课,我们对比一下urllib与requests的区别的是什么?以及urllib与requests哪种更好。
以上就是本站»requests安装命令(python变量名命名规则)的相关内容了,更多精彩请关注作者:万年知识
声明:本文由本站【创业者资源平台】作者编辑发布,更多技术关注万年技术!
标签: [db:关键词]
免责声明:本文系转载,版权归原作者所有;旨在传递信息,其原创性以及文中陈述文字和内容未经本站证实。







帮同学化妆最高日入近千 帮朋友化妆帮同学化妆最高日入近千?浙江大二女生冲上热搜,彩妆,妆容,模特,王
2023吉林省紧缺急需职业工种目录政策解读 2024张杰上海演唱会启东直通车专线时间+票价 马龙谢幕,孙颖莎显示统治力,林诗栋紧追王楚钦,国乒新奥运周期竞争已启动 全世界都被吓了一跳(惊吓全世界)


热门标签
热门文章
-
帮同学化妆最高日入近千 帮朋友化妆 24-10-07
-
2024杭甬运河宁波段恢复全线通航 杭甬运河属于几级航道 24-10-07
-
2024宁波羽毛球亚锦赛有哪些选手参加(宁波市羽毛球锦标赛) 24-10-07
-
通过对华电车征税提议 通过对华电车征税提议的建议 24-10-07
-
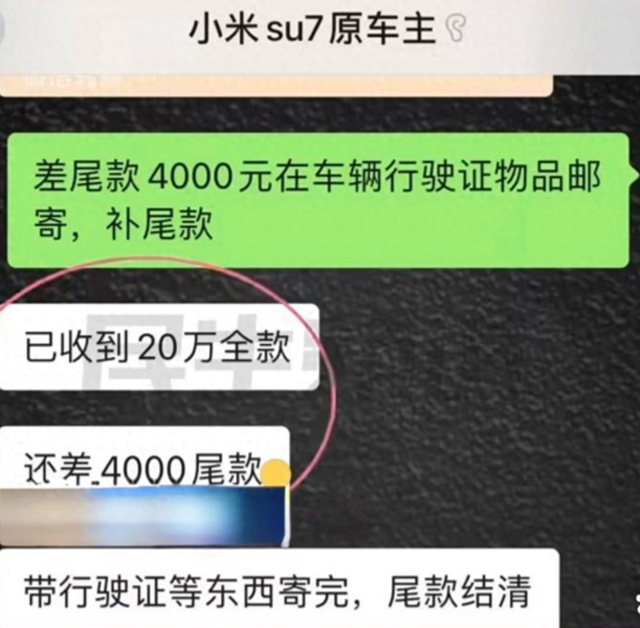
关于网传“男子接亲被加要18万彩礼”情况说明 24-10-07
-
释新闻|登上热搜的哀牢山在哪里,山里都有什么? 24-10-07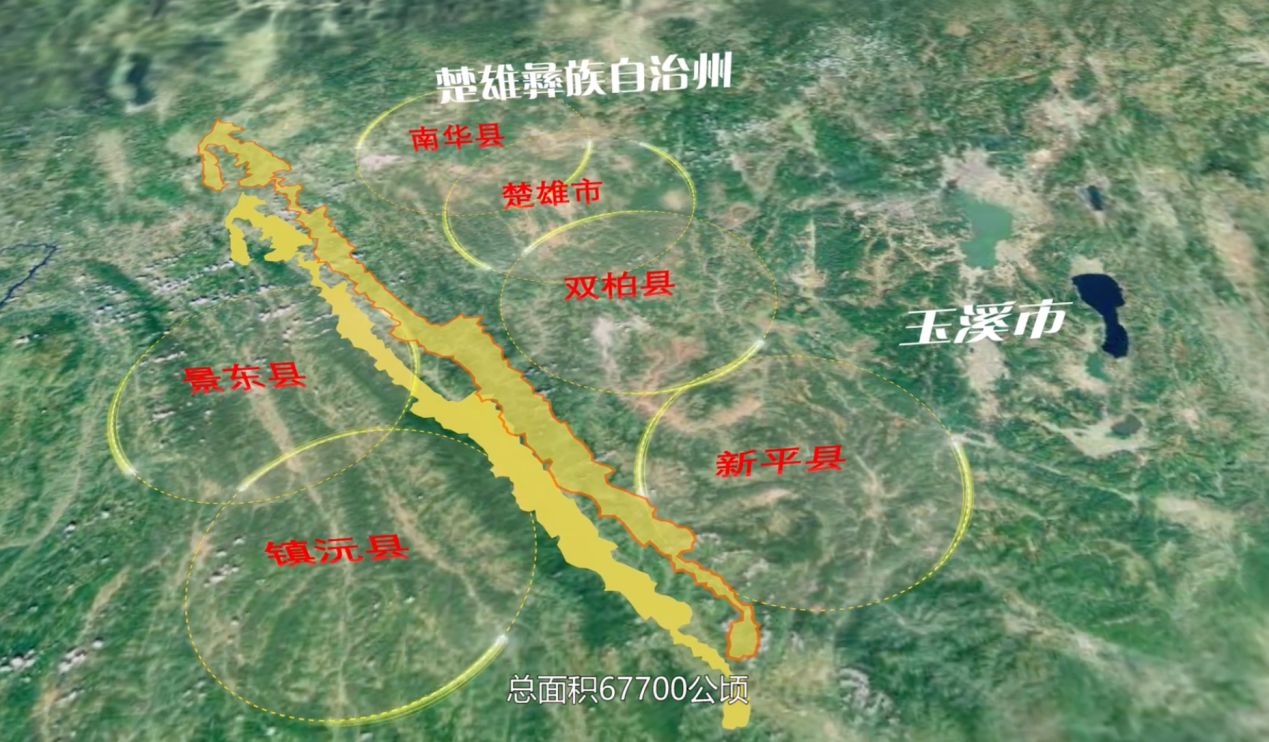
-
2024年江门市公墓清明节祭扫预约方式汇总 24-10-07
-
襄阳市图书馆10月活动(襄阳市图书馆国庆开放时间) 24-10-06
-
2023青岛凤凰音乐节官方有哪些售票平台? 24-10-06
-
民宿老板回应哀牢山爆火:国庆期间房源天天爆满,平时约90元一晚涨到约240元 24-10-06